
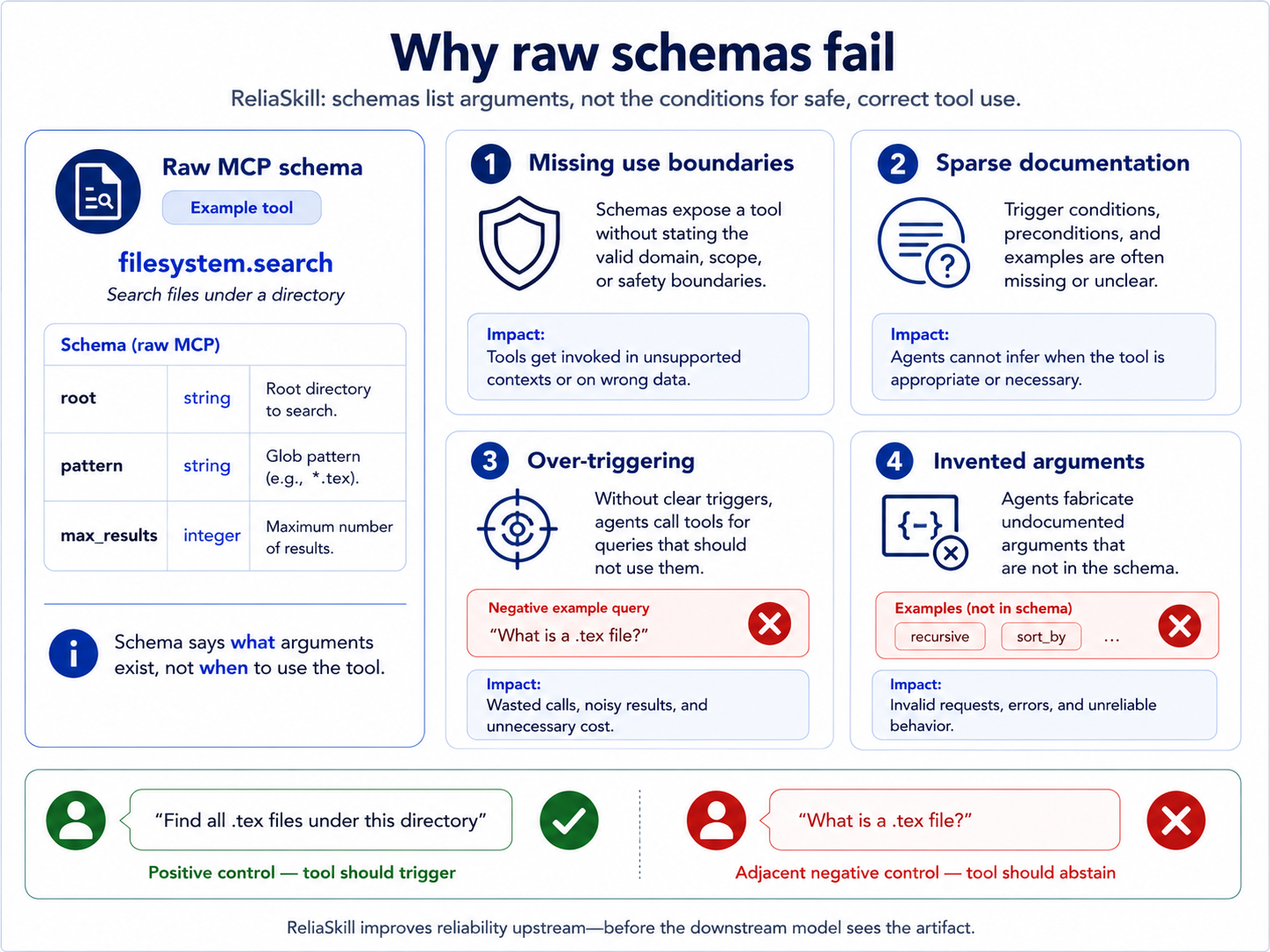
Missing use boundary
Sparse docs leave trigger conditions implicit, so a model has to infer the policy from a thin interface.
Research system for MCP skill cold-start
Pre-deployment validation, repair, and gating for reliable MCP-style tool-use skills.
ReliaSkill converts raw MCP-like schemas and sparse documentation into compact skill artifacts with explicit use boundaries, schema-faithful examples, validation reports, repair traces, reliability scores, and deployability decisions before downstream LLM agents see them.
{
"tool": "write_file",
"args": {
"path": "string",
"content": "string"
}
}
Problem
MCP schemas tell a model what arguments exist. They usually do not specify when the tool should fire, when it should abstain, or how an agent should interpret adjacent requests that look plausible but are out of scope.
Sparse docs leave trigger conditions implicit, so a model has to infer the policy from a thin interface.
Fluent generated skills may introduce fields that the underlying schema never accepted.
Agents can call a tool for adjacent requests where explanation, search, or abstention is the safer behavior.
Side-effect tools need explicit boundaries before deployment, not trust after one generated prompt.
Pipeline
ReliaSkill treats generated skills as candidates. Each candidate moves through normalization, generation, validation, behavior tests, targeted repair, and a final deployment gate.
Preserves the original schema and adds provenance, complexity, ambiguity, side-effect, and safety metadata.
normalizedCreates purpose, use boundaries, non-use boundaries, argument templates, and examples.
candidateChecks unsupported arguments, required fields, enum values, examples, contradictions, and compactness.
inspectedRuns positive controls and adjacent negative controls to measure utility and over-triggering risk.
testedPatches localized failing sections instead of defaulting to full skill regeneration.
patchedOutputs DEPLOY, REPAIR, or REJECT using explicit reliability evidence and repair traces.
gated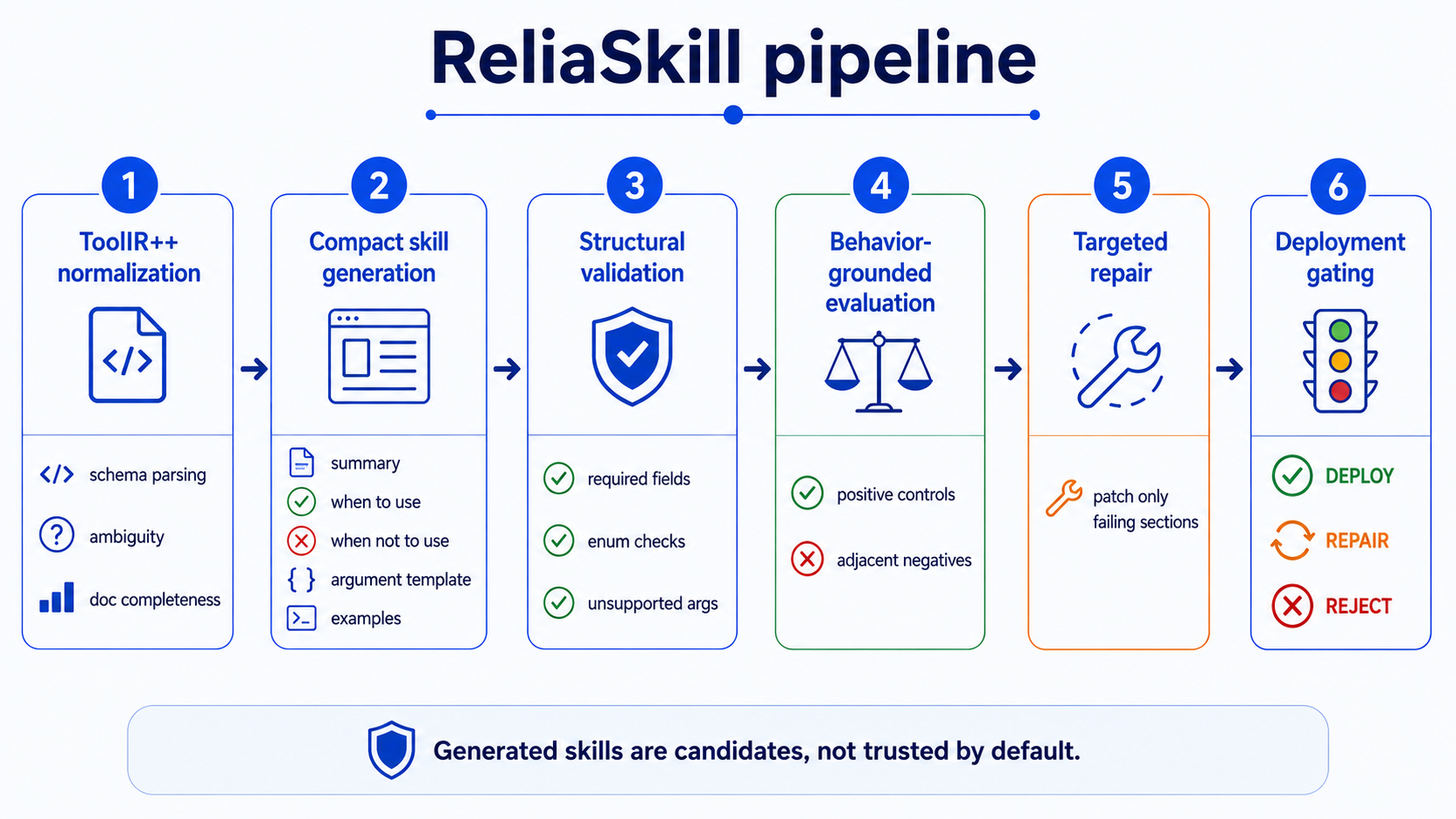
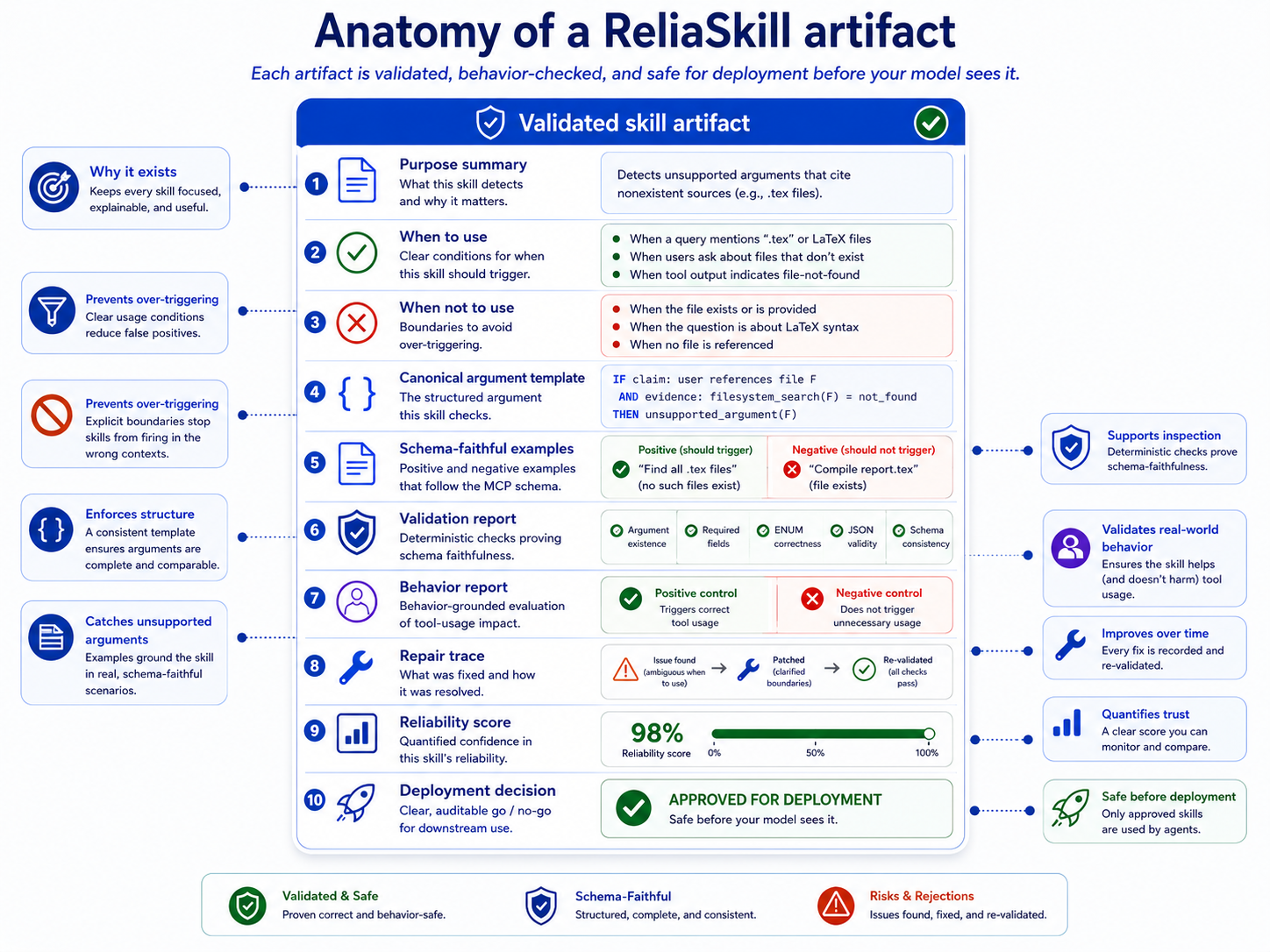
Artifact
ReliaSkill packages a compact agent-facing representation with machine-checkable evidence about schema faithfulness, behavior controls, repair history, and deployability.
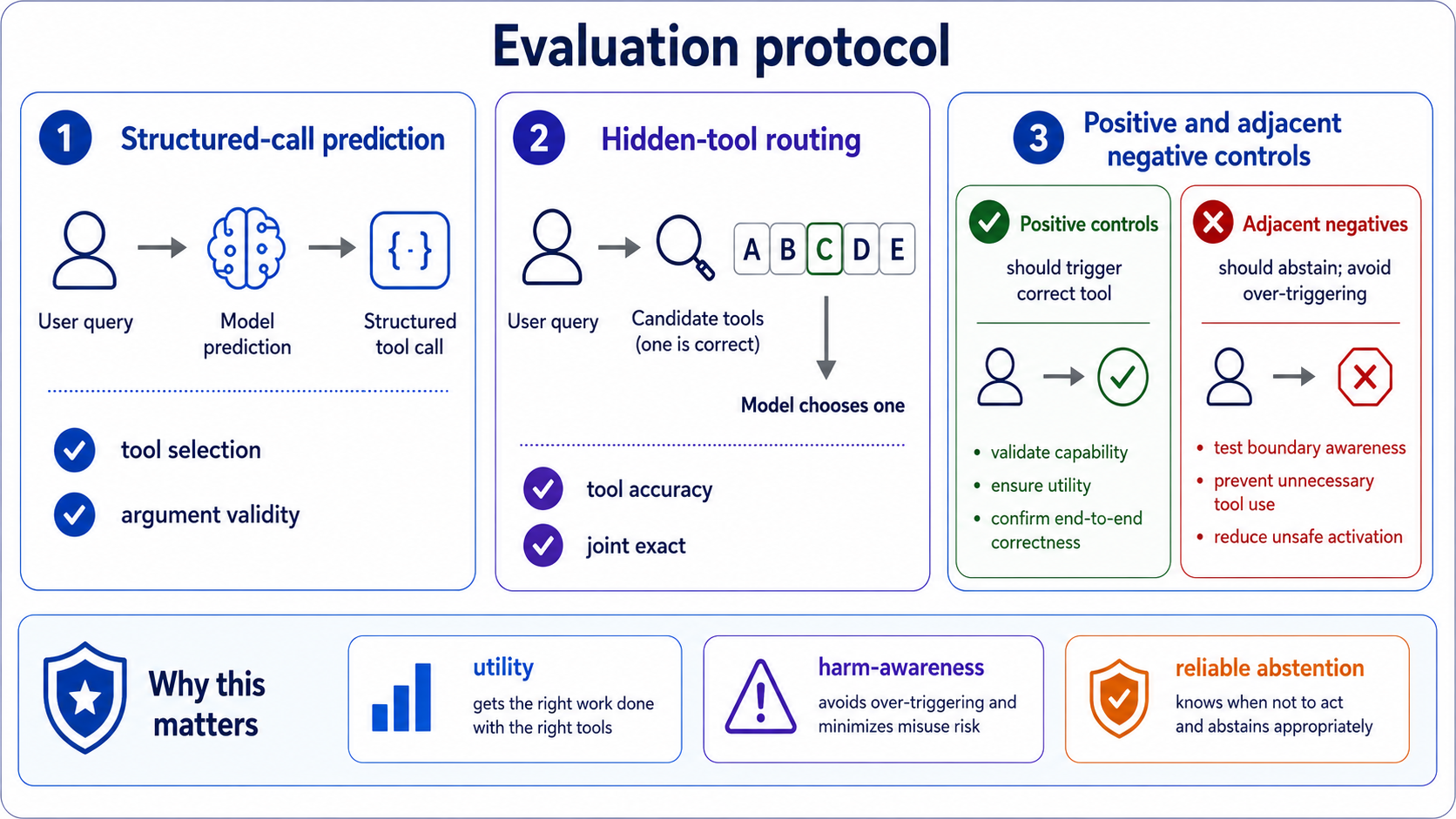
Evaluation
ReliaSkill evaluates whether a representation helps models produce the correct call, select the right hidden tool, and abstain on adjacent negative controls.
Checks whether the predicted tool call matches the gold call and whether arguments are parseable and schema-faithful.
Exercise intended use cases with gold tools and gold arguments across difficulty tiers.
Test abstention on near-miss, explanation-versus-action, read-versus-write, and missing-information cases.
Measures tool selection and joint route-plus-argument correctness among candidate tools with hard distractors.
Does the representation help the model assemble the right call?
Does the representation avoid activating on adjacent out-of-scope requests?
Results
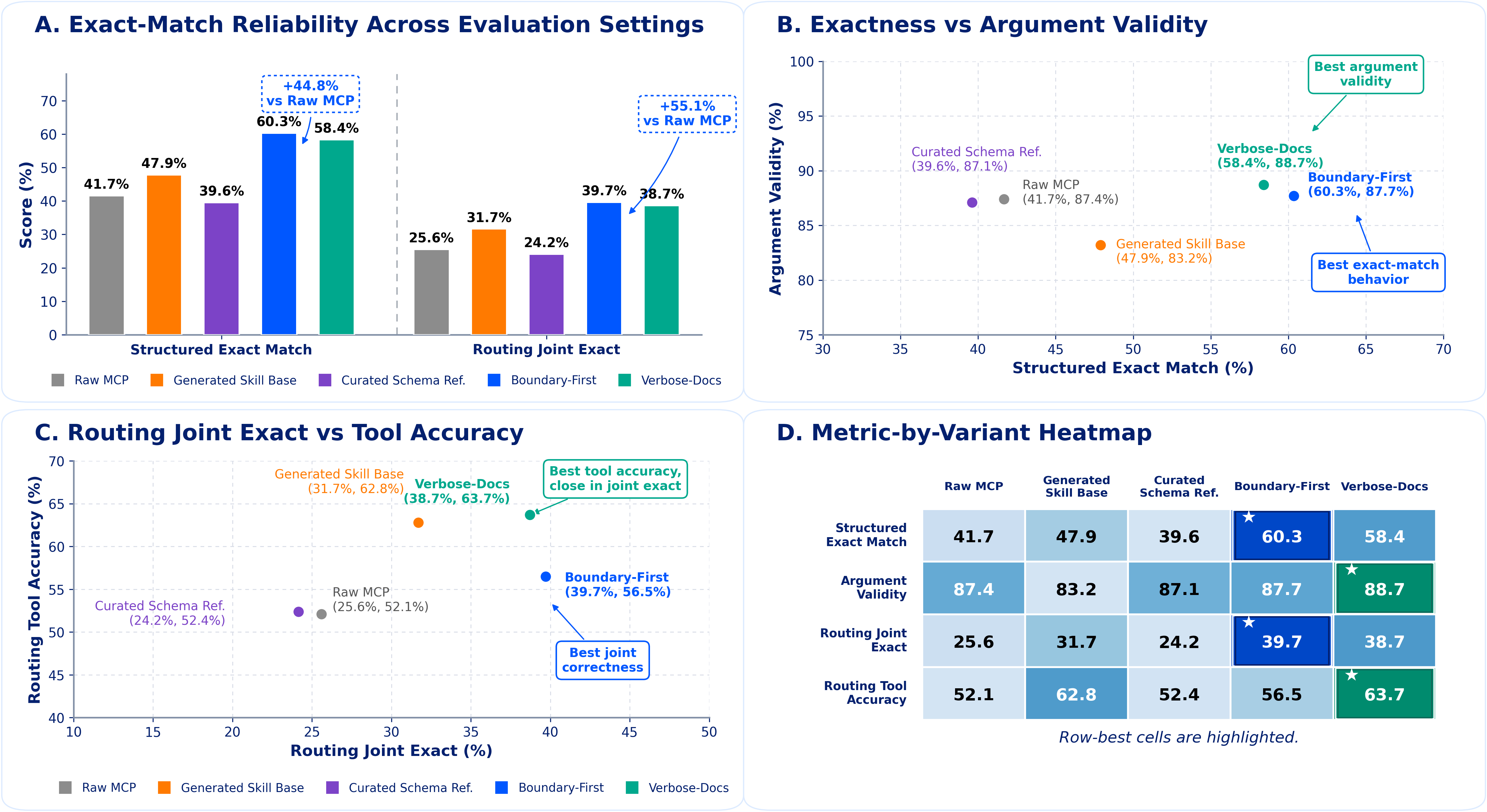
The evaluation compares five tool-facing representations while holding the downstream predictor fixed within each comparison. Boundary-first is the primary ReliaSkill rendering, with verbose docs reported as a close secondary variant.
| Condition | Llama3.2-1B | Qwen2.5-1.5B | Gemma2-2B | Phi-3.5-mini | Qwen2.5-7B | Llama3.1-8B | Gemma2-9B | Mean |
|---|---|---|---|---|---|---|---|---|
raw_mcp | 33.42 | 38.58 | 43.80 | 33.97 | 53.02 | 39.93 | 48.88 | 41.66 |
generated_skill_base | 37.76 | 34.31 | 43.93 | 42.44 | 63.32 | 56.81 | 56.75 | 47.90 |
curated_schema_reference | 38.71 | 37.29 | 30.37 | 32.61 | 53.83 | 37.69 | 46.78 | 39.61 |
skill_prompt_boundary_first | 52.81 | 61.63 | 52.07 | 63.73 | 70.37 | 58.37 | 63.39 | 60.34 |
skill_prompt_verbose_docs | 52.20 | 56.14 | 52.54 | 62.17 | 67.86 | 57.90 | 60.07 | 58.41 |
Boundary-first reaches a 60.34% seven-model mean, a 44.8% relative improvement over raw MCP exposure.
| Condition | Llama3.2-1B | Qwen2.5-1.5B | Gemma2-2B | Phi-3.5-mini | Qwen2.5-7B | Llama3.1-8B | Gemma2-9B | Mean |
|---|---|---|---|---|---|---|---|---|
raw_mcp | 22.24 | 14.44 | 21.02 | 25.22 | 34.31 | 27.86 | 34.03 | 25.59 |
generated_skill_base | 26.24 | 17.02 | 26.98 | 31.32 | 42.24 | 39.39 | 38.71 | 31.70 |
curated_schema_reference | 24.00 | 13.69 | 15.19 | 23.73 | 32.20 | 26.64 | 33.69 | 24.16 |
skill_prompt_boundary_first | 37.76 | 31.53 | 31.80 | 45.29 | 45.42 | 42.03 | 44.07 | 39.70 |
skill_prompt_verbose_docs | 35.19 | 33.02 | 34.03 | 42.71 | 44.75 | 40.07 | 41.29 | 38.72 |
Boundary-first reaches a 39.70% routing Joint Exact mean, while verbose docs is close at 38.72% and wins for Qwen2.5-1.5B and Gemma2-2B.
| System | Joint EM | Argument Validity | Selection Accuracy |
|---|---|---|---|
| Full ReliaSkill | 21.12% | 52.78% | 31.39% |
| w/o Repair | 20.41% | 53.05% | 27.39% |
| w/o Validation | 18.85% | 50.07% | 27.36% |
| w/o Examples | 15.73% | 41.22% | 25.80% |
Full ReliaSkill improves Joint Exact Match from raw MCP at 17.15% to 21.12%, with Argument Validity rising from 43.66% to 52.78%.
skill_prompt_boundary_first is the primary ReliaSkill variant in the paper and has the best seven-model mean on both main metrics.
Raw MCP exposure is the weakest main interface on average, and generated skills improve results before further rendering choices are applied.
Boundary-first and verbose-doc variants share underlying skill content; their differences isolate prompt rendering policy.
No observed harmful activation on held-out negative controls is a benchmark result, not a deployment guarantee.
Implementation
The repository includes parsing, generation, validation, controls, repair, gating, routing, conversion, live sandbox, and analysis components.
Quick start
The commands below are copied from the README and use the repository's existing scripts.
python -m venv .venv
.\.venv\Scripts\Activate.ps1
python -m pip install --upgrade pip
python -m pip install -r requirements.txtpython scripts\run_reliability_pipeline.py --config configs\experiment.reliability.heuristic.sample.jsonpython scripts\run_benchmark_eval.py
python scripts\run_routing_eval.pypython -m unittest discover -s tests -vGitHub Pages
This showcase lives in docs/ and can be served by GitHub Pages from the main / docs source. It uses plain HTML, CSS, and JavaScript, with no backend and no build step.